Overview
acciddasuite builds infectious disease forecasts in a
few steps:
-
get_data()orcheck_data(): fetch or validate surveillance data. -
get_ncast()(optional): correct recent weeks for reporting delays. -
get_cv()(optional): evaluate candidate models by time series cross-validation. -
get_fcast(): ensemble the best models into a forward-looking forecast.
The package relies on the fable modeling
framework and follows the standard forecasting workflow described by Hyndman &
Athanasopoulos (2021). The overall goal is to provide public health
professionals with an easily-adoptable approach to generating,
evaluating forecasts, and visualizing infectious disease forecasts.
To get more information about how to know whether forecasting is the best approach for your task, follow the steps in this article.
Step 1: Get data
We fetch weekly COVID-19 hospital admissions for New York from the CDC
NHSN via epidatr.
Setting revisions = TRUE retrieves the full revision
history (i.e. all past versions of the data), which is needed
for nowcasting.
get_data() returns a validated accidda_data
object:
library(acciddasuite)
df <- get_data(pathogen = "covid", geo_value = "ny", revisions = TRUE)
df
#> <accidda_data>
#>
#> Location: NY
#> Target: wk inc covid hosp
#> Window: 2020-08-08 to 2026-06-06 ( 305 dates )
#> Interval: 7 days
#> History: TRUE ( 2024-11-17 to 2026-06-07 )You can also bring your own data. Just pass it
through check_data(). See
vignette("external_data") for formatting details.
Step 2: Nowcasting (optional)
The most recent weeks of surveillance data are almost always too low because hospitals are still filing late reports (right truncated). If you feed these raw counts into a forecaster, predictions will be biased downward.
get_ncast() estimates what the recent counts will look
like once all reports arrive. With the default
max_delay = 4, the last 4 weeks are corrected; everything
before that is left untouched.
ncast <- get_ncast(df)
ncast
#> <accidda_ncast>
#>
#> Location: NY
#> Target: wk inc covid hosp
#> Nowcasted 2 weeks: 2026-05-30 to 2026-06-06
#>
#> $data corrected series (305 rows)
#> $plot nowcast visualisation
ncast$plot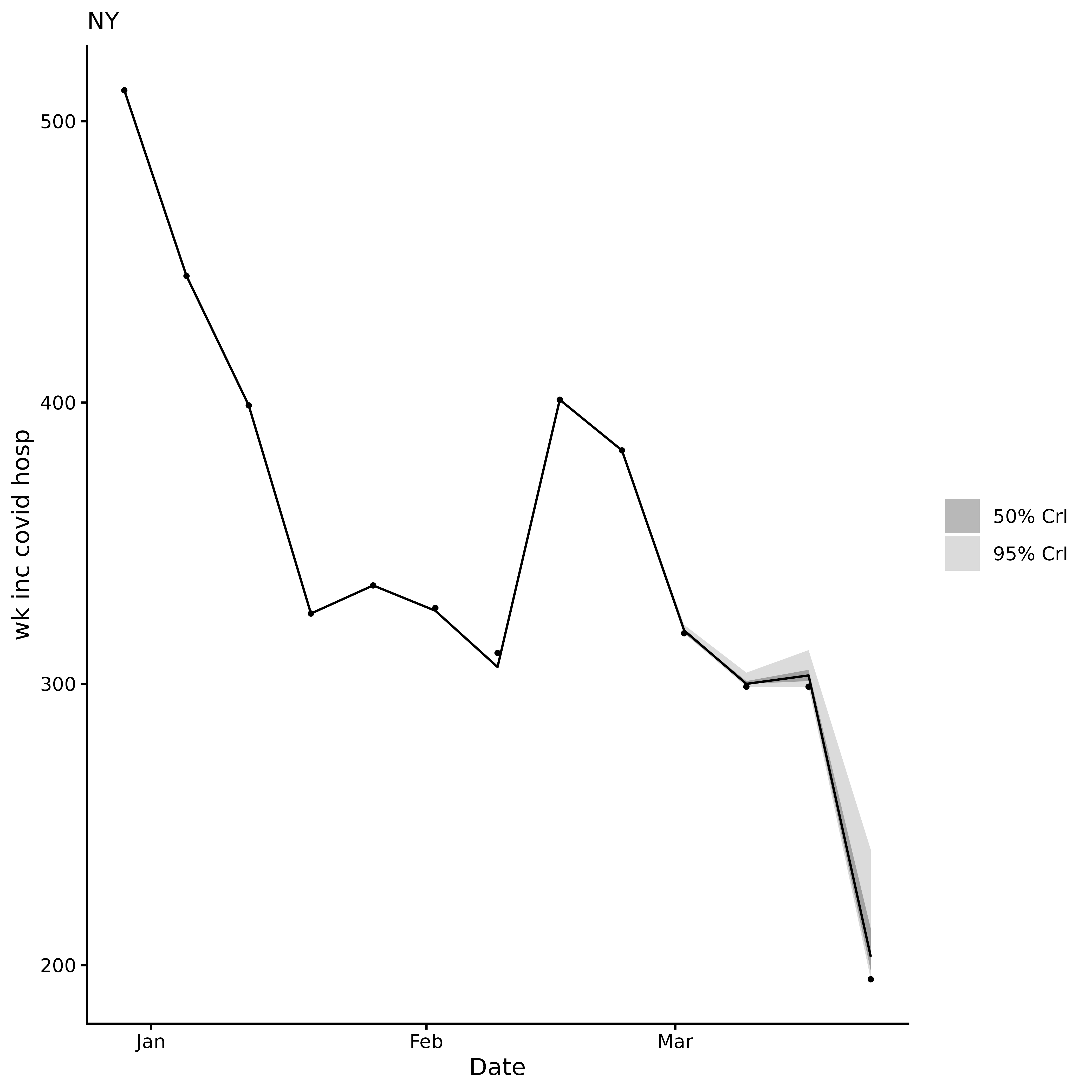
The corrected ncast$data contains two extra columns:
ncast_lower and ncast_upper (95% CrI) for the
corrected weeks. get_fcast() detects these automatically
and uses them to propagate nowcasting uncertainty into the final
forecast.
Step 3: Forecasting
Forecasting is split into two steps:
-
get_cv()— model selection: time series cross-validation on the full (median corrected) series, starting fromeval_start_date. Models are ranked by WIS and interval coverage. -
get_fcast()— final forecast: reuses the ranking to ensemble the besttop_nmodels and projectshweeks into the future. When nowcast columns are present, the forecast is produced from three baselines (lower, median, and upper nowcast estimates) and pooled, so prediction intervals reflect both model uncertainty and nowcast uncertainty.
We set eval_start_date to mark the start of the
evaluation window. At least 52 weeks of data must precede this date.
eval_start_date <- max(ncast$data$target_end_date) - 28Default models are:
NAIVE(Naïve / random walk): Carries the last observed value forward. The simplest possible baseline.ETS(Exponential Smoothing): A weighted average where recent weeks matter more than older ones. Adapts to trends and seasonal patterns.THETA: Splits the data into a long-term trend and short-term fluctuations, forecasts each separately, then combines them.ARIMA: Learns repeating patterns from past values to predict future ones. Auto-configured to find the best fit.
cv <- get_cv(
ncast,
eval_start_date = eval_start_date,
h = 4
)
cv
#> <accidda_cv>
#>
#> Models ranked (cross-validation):
#> # A tibble: 3 × 2
#> model_id wis
#> <chr> <dbl>
#> 1 ETS 29.4
#> 2 THETA 34.1
#> 3 NAIVE 35.1
#>
#> Evaluated from 2026-05-09 | horizon 4 weeks | NY
#>
#> Contents:
#> $forecasts per-origin forecasts (model_out_tbl)
#> $oracle observed truth (oracle_output)
#> $score model ranking table
#> $models model specifications
#> $meta eval_start_date, h, location, target, interval
fcast <- get_fcast(cv, top_n = 3)
fcast
#> <accidda_fcast>
#>
#> Models ranked (cross-validation):
#> # A tibble: 3 × 2
#> model_id wis
#> <chr> <dbl>
#> 1 ETS 29.4
#> 2 THETA 34.1
#> 3 NAIVE 35.1
#>
#> Forecast horizon:
#> From: 2026-06-13
#> To: 2026-07-04
#>
#> Contents:
#> $hub hub forecast object (model_out_tbl, oracle_output)
#> $score model ranking table, or NULL
#> $meta models, top_n, h, location, target, interval, nowcastAdding custom models
Any model compatible with the fable framework can
be passed to get_cv() via models. Compose with
default_models() to keep the built-ins alongside your
own:
library(fable)
library(fable.prophet)
library(EpiEstim)
library(projections)
my_models <- c(
default_models(),
list(
CUSTOM_ARIMA = ARIMA(observation ~ pdq(1,1,0)),
PROPHET = prophet(observation ~ season("year")),
EPIESTIM = EPIESTIM(observation, mean_si = 3, std_si = 2, rt_window = 7)
)
)
cv <- get_cv(
ncast,
eval_start_date = eval_start_date,
h = 3,
models = my_models
)
fcast <- get_fcast(cv, top_n = 3)Submit to RespiLens
RespiLens is a platform for
sharing respiratory disease forecasts. Use to_respilens()
to export the forecast as JSON for upload to MyRespiLens.
to_respilens(fcast, "respilens.json")